 码农code之路
码农code之路1.简介
后置处理器是在发出“取样器请求”之后执行一些操作。取样器用来模拟用户请求,有时候服务器的响应数据在后续请求中需要用到,我们的势必要对这些响应数据进行处理,后置处理器就是来完成这项工作的。例如系统登录成功以后我们需要获取SessionId,在后面的业务操作中服务器会验证这个SessionId,获取SessionId这个功能过程就可以用后置处理器中的正则表达式提取器来完成。
2.预览后置处理器
首先我们来看一下JMeter的后置处理器,路径:线程组(用户)->添加->后置处理器();我们可以清楚地看到JMeter5中共有11个后置处理器(不包括jp@gc开头的后置处理器,这个是宏哥安装的插件),如下图所示:
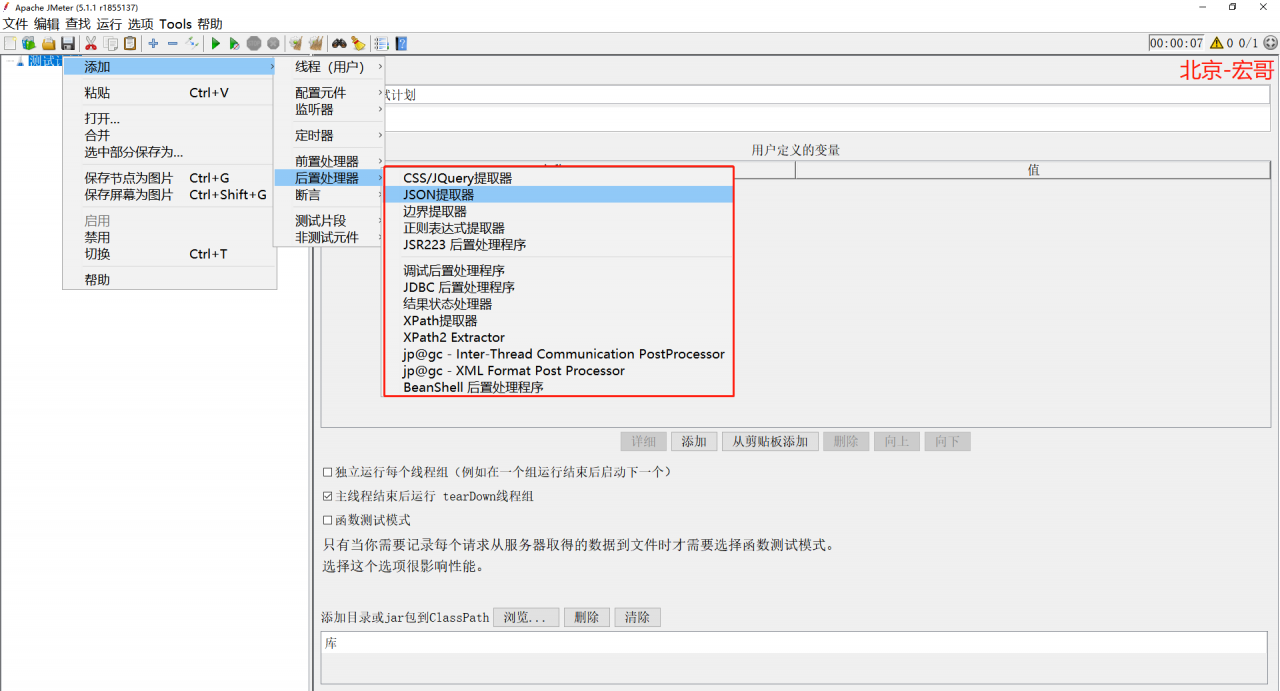
如果上图您看得不是很清楚的话,宏哥总结了一个思维导图,关于JMeter5的前置处理器类型,如下图所示:
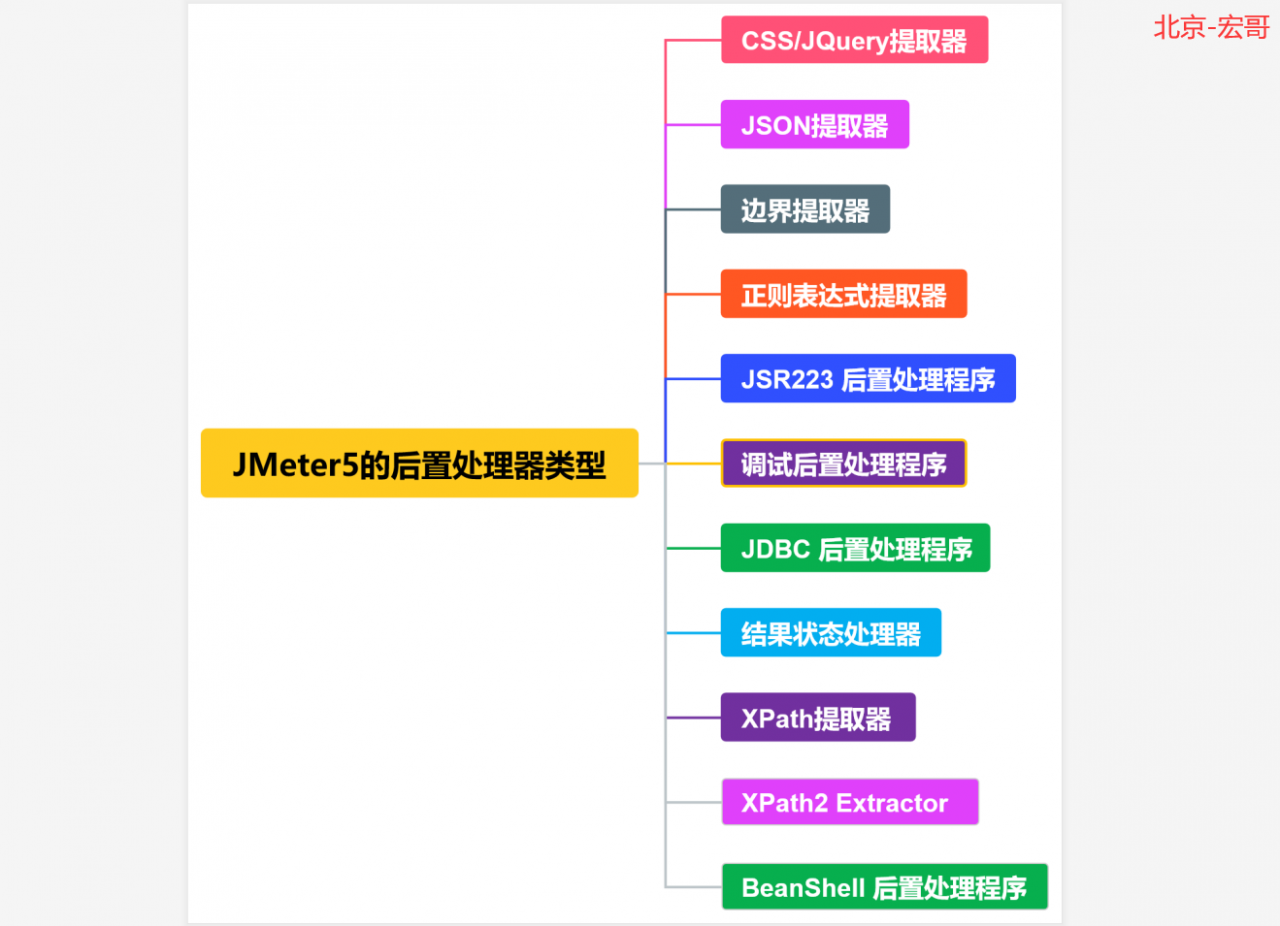
通过以上的了解,我们对后置处理器有了一个大致的了解和认识。下面宏哥就给小伙伴或则童鞋们分享讲解一些通常在工作中会用到的后置处理器。
3.常用后置处理器详解
这一小节,宏哥就由上而下地详细地讲解一下常用的后置处理器。
3.1JSR223 后置处理程序
JSR223后置处理程序,用法和JSR223 PreProcessor类似,可以参考宏哥的这一篇文章:Jmeter(十六) – 从入门到精通 – JMeter前置处理器(详解教程)
1、我们先来看看这个JSR223 后置处理程序长得是啥样子,路径:线程组 > 添加 > 后置处理器 > JSR223 后置处理程序,如下图所示:
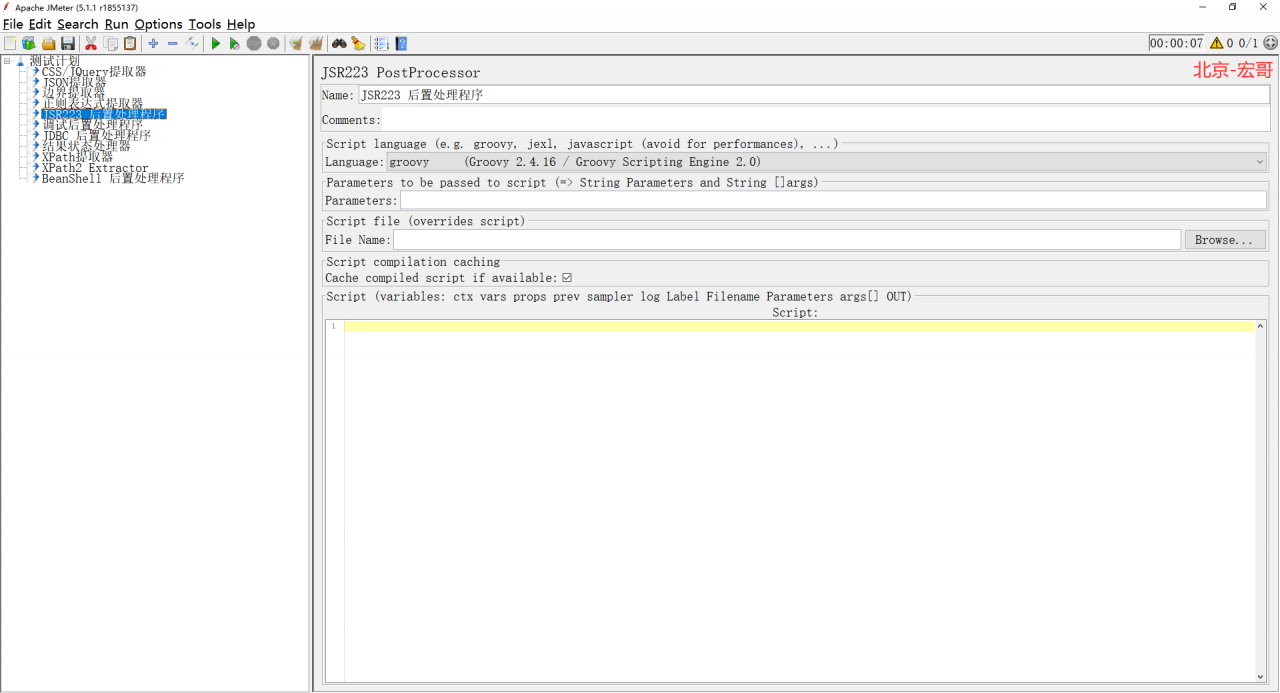
2、关键参数说明如下:
Name:名称,可以随意设置,甚至为空;
Comments:注释,可随意设置,可以为空;
parameter:要传递到脚本文件或脚本的参数列表;
file name:用于执行的脚本文件,若没有脚本文件,将执行脚本;
Script:传递给JSR223执行的脚本;如果提供了脚本文件,则执行脚本文件,否则执行脚本。
3.2调试后置处理程序
调试后置处理程序,使用正则表达式为从另一个HTTP请求中提取的HTTP参数指定动态值,配合regular expression extractor使用。暂时没找到好的例子,后面想到补充。。
1、我们先来看看这个调试后置处理程序长得是啥样子,路径:线程组 > 添加 > 后置处理器 > 调试后置处理程序,如下图所示:
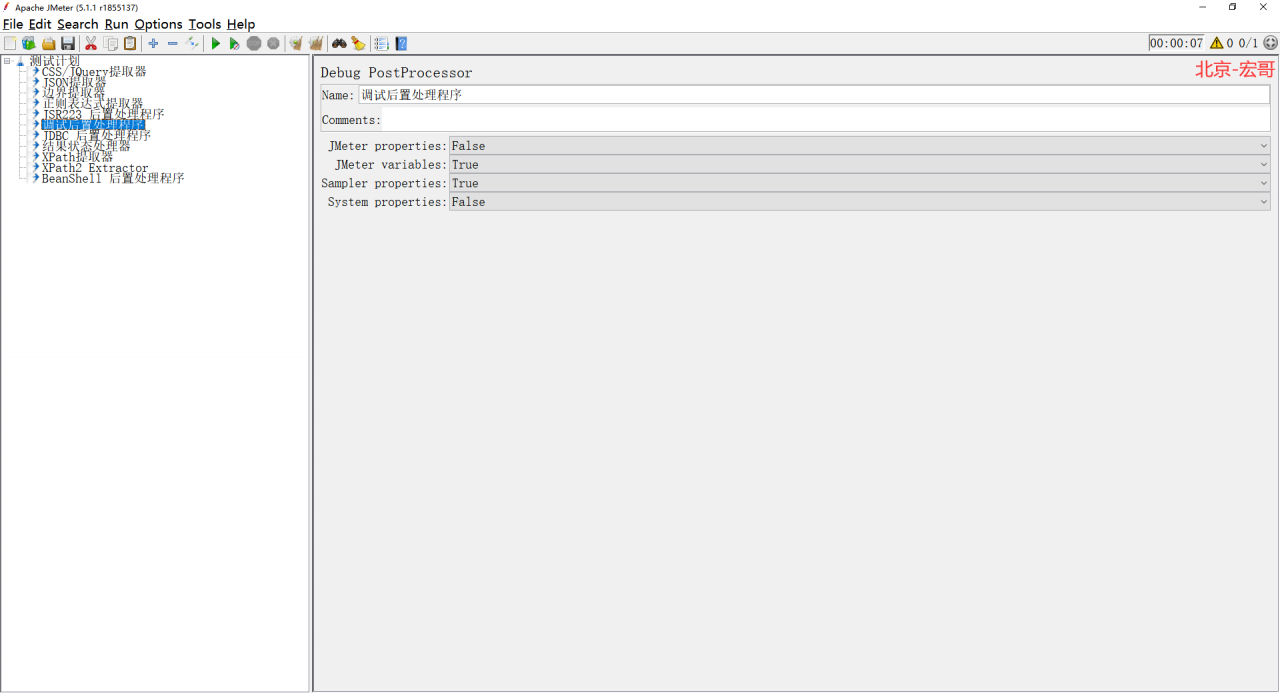
2、关键参数说明如下:
Name:名称,可以随意设置,甚至为空;
Comments:注释,可随意设置,可以为空;
Regular Expression Reference Name:调用的正则表达式提取器中的引用名称;
Parameter names regexp group number:用于提取参数名称的正则表达式的组编号;
Parameter values regex group number:用于提取参数值的正则表达式的组编号。
3.3JDBC 后置处理程序
JDBC 后置处理程序,实际上JIBC PostProcessor就是一个JDBC Request,它与JDBC Request功能相同,都可以执行SQL语句。在测试的过程中可能会遇到这样的测试场景:我们用JDBC Request修改了一些数据,当测试完成后,我们希望还原到原先状态,此时我们可以用JDBC PostProcessor来完成,当然用JDBC Request也可以完成。具体的JDBC PostProcessor的使用参考宏哥关于JDBC Request的这篇文章:Jmeter(七) – 从入门到精通 – 建立数据库测试计划实战<MySQL数据库>(详解教程)。
1、我们先来看看这个JDBC 后置处理程序长得是啥样子,路径:线程组 > 添加 > 后置处理器 > JDBC 后置处理程序,如下图所示:
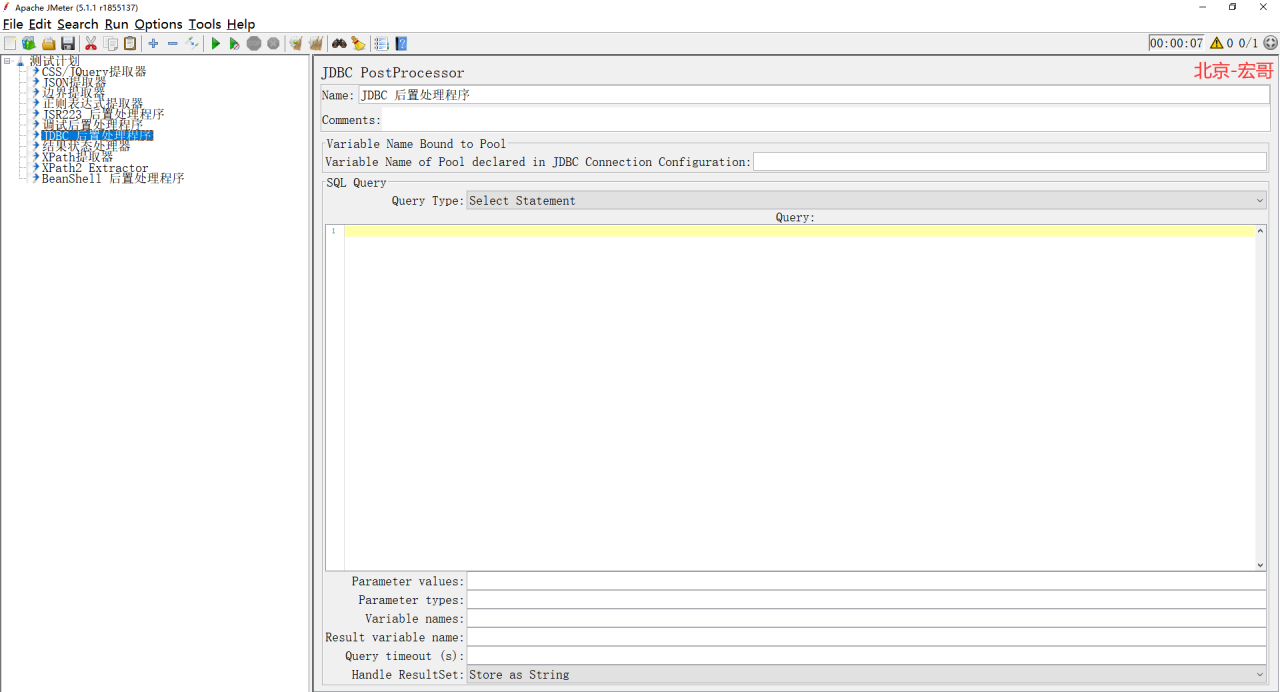
3.4结果状态处理器
结果状态处理器,实际上在测试的时候我们也经常会遇到这样的测试场景:在一些测试用例失败之后我们需要进行一些操作,例如停止测试,这里可以使用结果状态处理器。
1、我们先来看看这个结果状态处理器长得是啥样子,路径:线程组 > 添加 > 后置处理器 > 结果状态处理器,如下图所示:
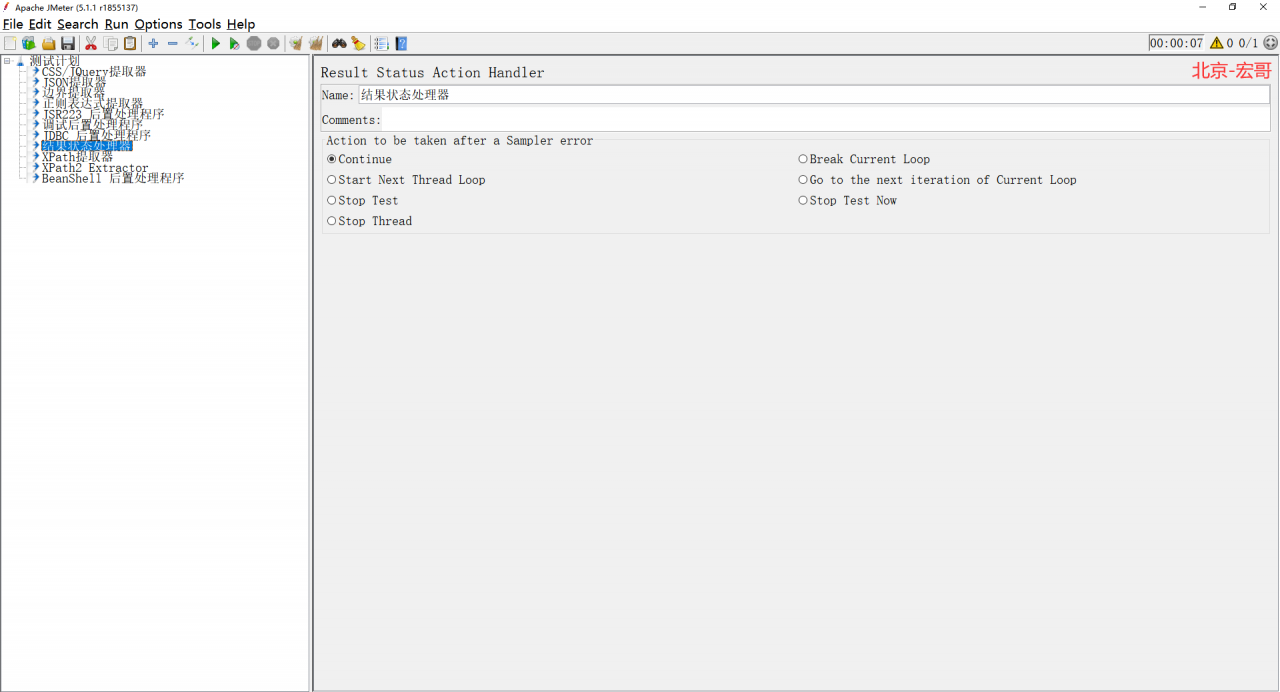
2、关键参数说明如下:
Name:名称,可以随意设置,甚至为空;
Comments:注释,可随意设置,可以为空;
Language:语言,开发脚本选择的语言,使用的JSR223语言,可根据需要选择;
Parameters:参数,传递给脚本的参数;
File Name:文件名,本地开发的脚本文件(会覆盖在JMeter里编写的脚本);
Script compilation caching:存储编译的脚本,默认勾选;
Script:要运行脚本。编写脚本的区域。
3.5XPath提取器
Xpath提取器,如果请求返回的消息为xml或html格式的,可以用XPath提取器来提取需要的数据。
1、我们先来看看这个 Xpath提取器长得是啥样子,路径:线程组 > 添加 > 后置处理器 > Xpath提取器,如下图所示:
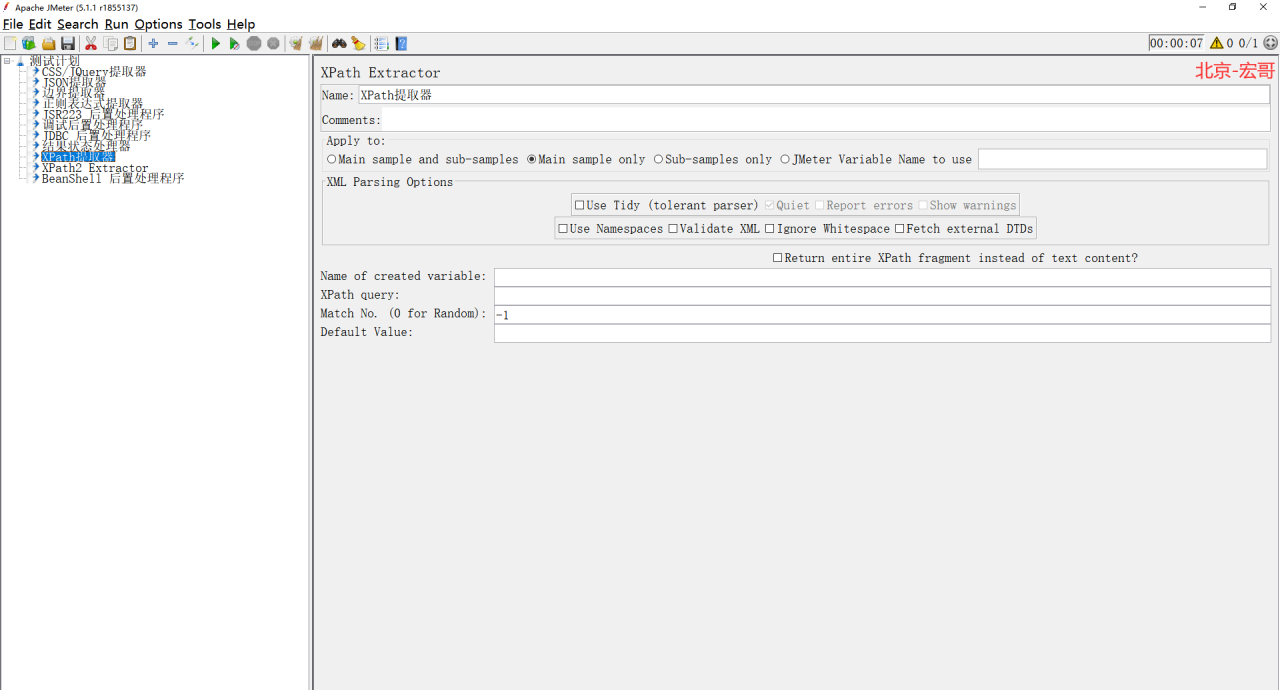
2、关键参数说明如下:
APPly to:作用范围(返回内容的断言范围)
Main sample and sub-samples:作用于父节点的取样器及对应子节点的取样器
Main sample only:仅作用于父节点的取样器
Sub-samples only:仅作用于子节点的取样器
JMeter Variable:作用于jmeter变量(输入框内可输入jmeter的变量名称)
XML Parsing Options:要解析的XML参数
UseTidy:当需要处理的页面是HTML格式时,必须选中该选项;如果是XML或XHTML格式(例如RSS返回),则取消选中;
Quiet表示只显示需要的HTML页面,
Report errors表示显示响应报错,
Show warnings表示显示警告;
Use Namespaces:如果启用该选项,后续的XML解析器将使用命名空间来分辨;
Validate XML:根据页面元素模式进行检查解析;
Ignore Whitespace:忽略空白内容;
Fetch external DTDs:如果选中该项,外部将使用DTD规则来获取页面内容;
Return entire XPath fragment of text content:返回文本内容的整个XPath片段;
Reference Name:存放提取出的值的参数。
XPath Query:用于提取值的XPath表达式。语法参考:XPath
匹配数字:取第几个匹配结果,0随机,-1全部,1代表第一个,2代表第二个,….以此类推
Default Value:参数的默认值。
3.5.1实例
1、新建测试计划,线程组下添加1个取样器 天气预报,如下图所示:
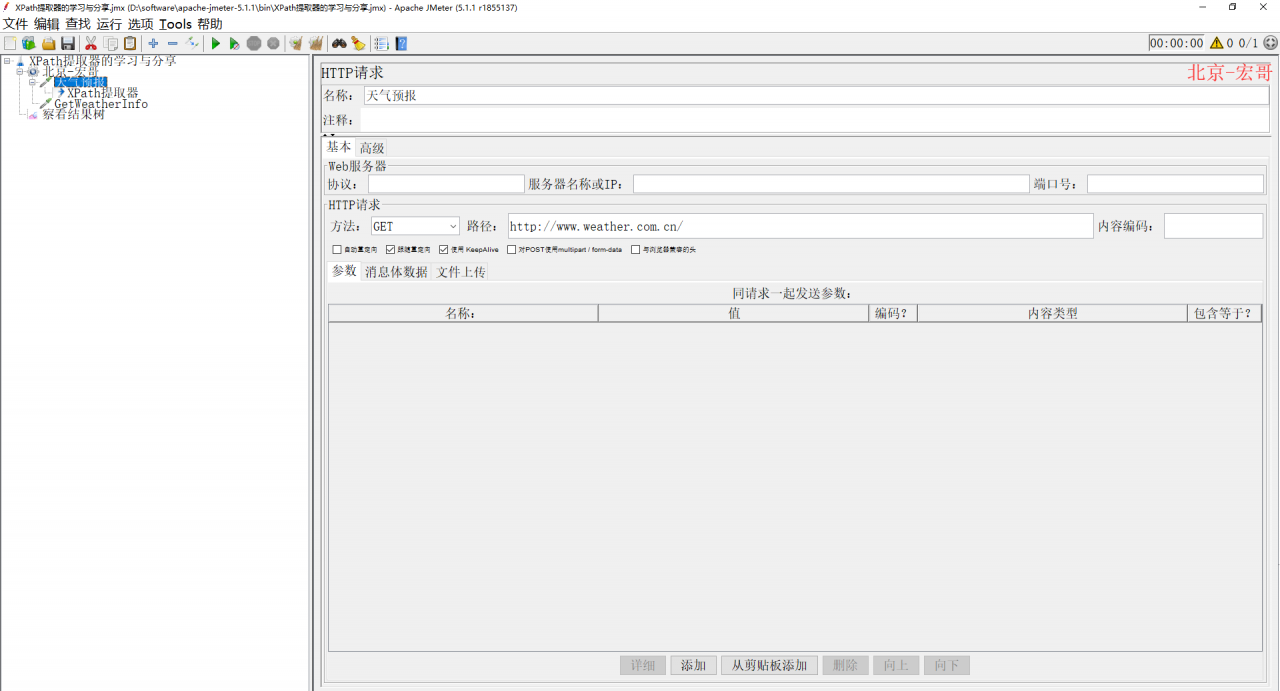
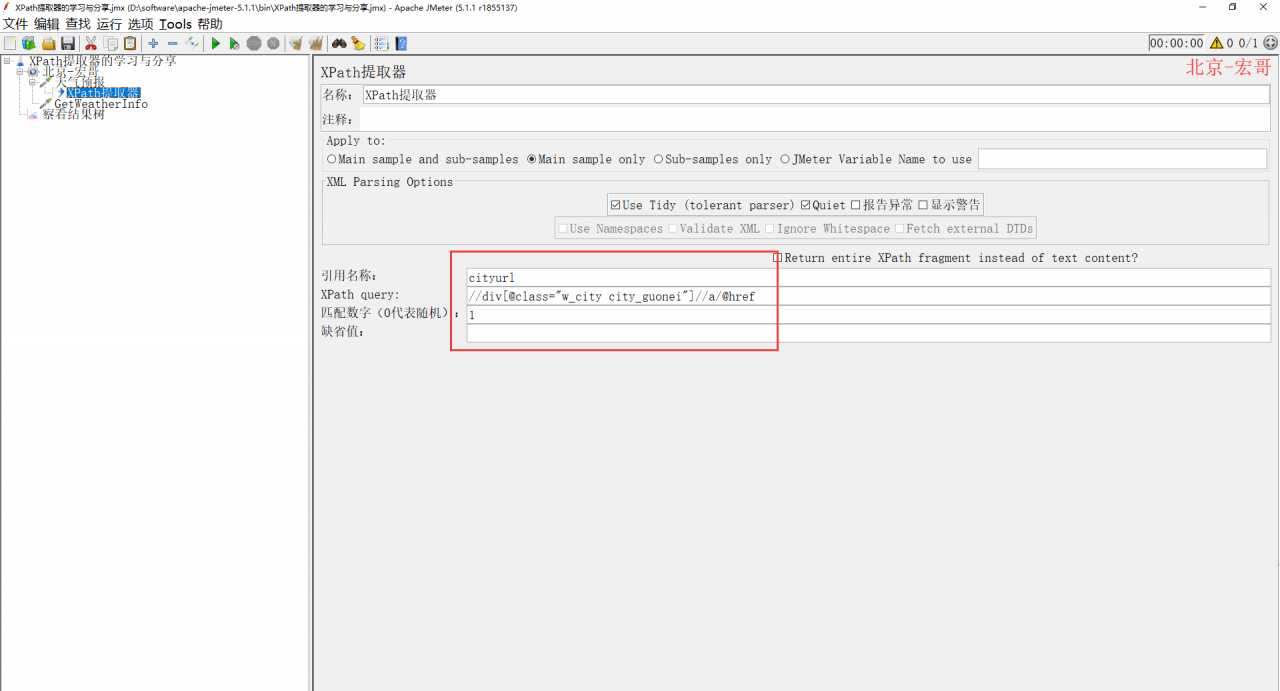
2、天气预报返回HTML,然后再添加xpath提取器,如下图所示:
举例://div[@class=’w_city city_guonei’]//a/@href
选取div下带有class属性为w_city city_guonei的href属性节点。
注释://div选取了div节点的所有子节点
@选取属性
/@href 从根节点选取所有的href属性
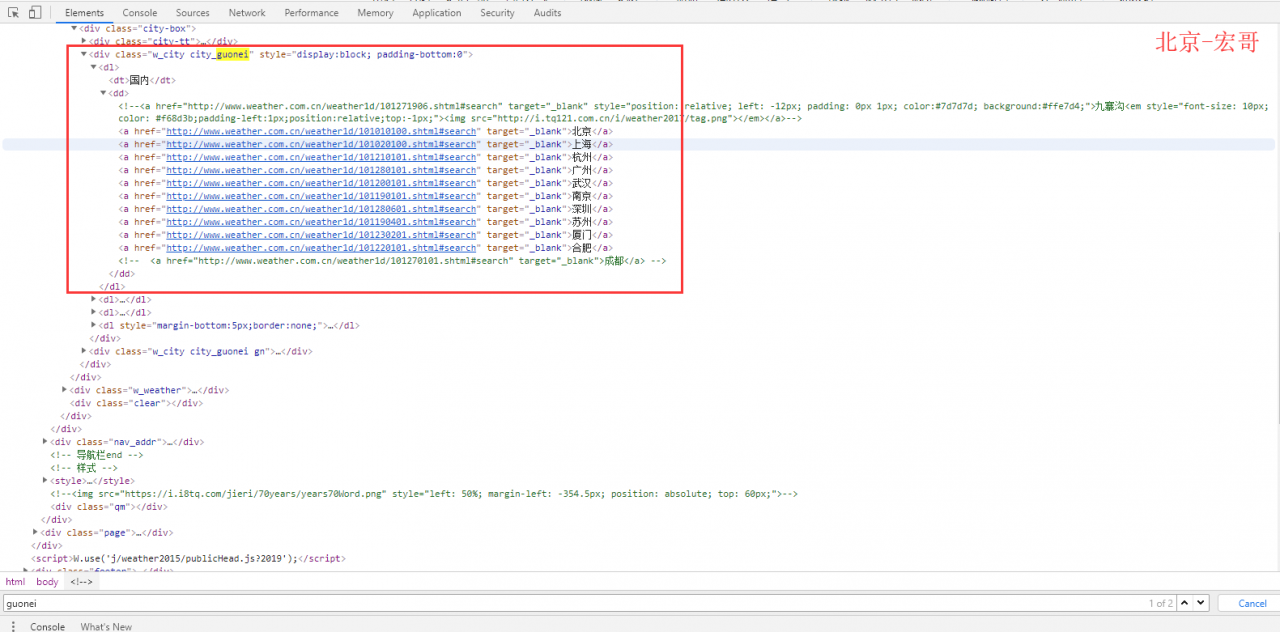
Xpath提取器设置
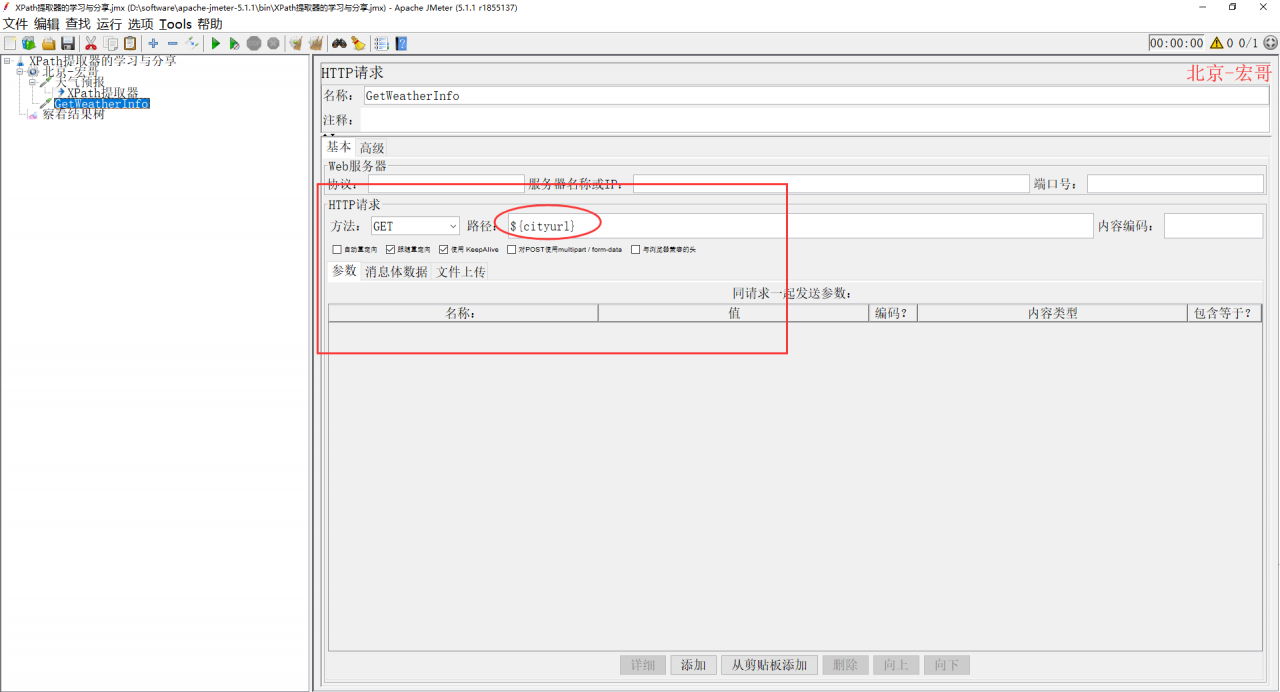
3、继续添加GetWeatherInfo取样器,获取xpath提取到的参数,如下图所示:
4、配置好以后,点击“保存”,运行JMeter,查看表格结果(取样器访问博客园首页和访问度娘间隔3s),如下图所示:
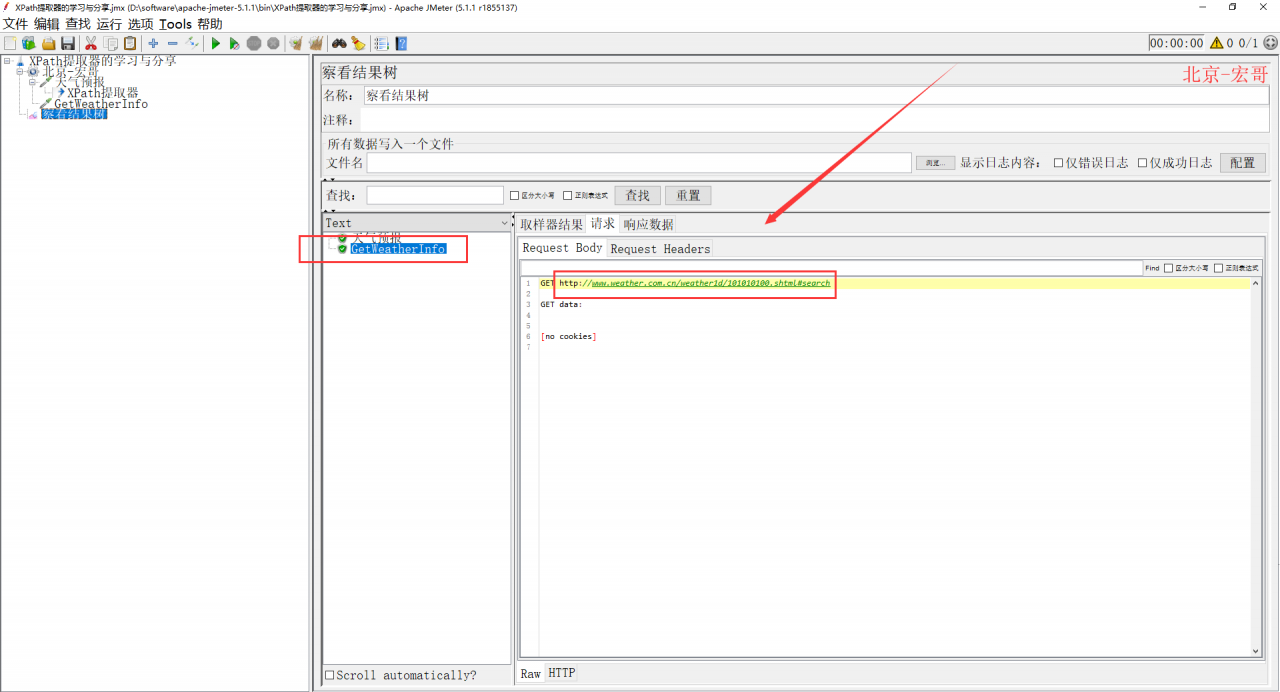
3.6XPath2 Extractor
Xpath2提取器,虽然JMeter官方文档说可以使用XPath2查询语言从结构化响应(XML或(X)HTML)中提取值,但目前测试只支持从XML响应中提取值;从HTML中提取会报错,这个可以通过查看结果树中选择XPath2 Tester来验证。
1、我们先来看看这个 Xpath2提取器长得是啥样子,路径:线程组 > 添加 > 前置处理器 > Xpath2提取器,如下图所示:
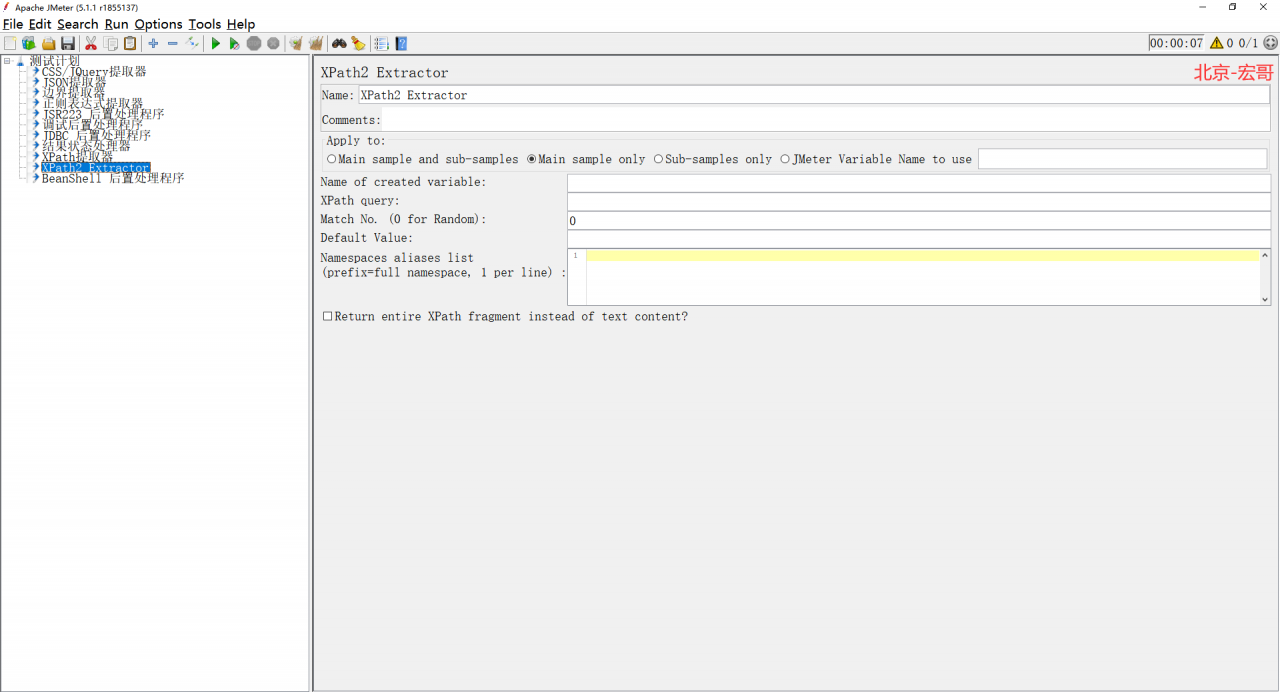
2、关键参数说明如下:
APPly to:作用范围(返回内容的断言范围)
Main sample and sub-samples:作用于父节点的取样器及对应子节点的取样器
Main sample only:仅作用于父节点的取样器
Sub-samples only:仅作用于子节点的取样器
JMeter Variable:作用于jmeter变量(输入框内可输入jmeter的变量名称)
Return entire XPath fragment of text content:返回文本内容的整个XPath片段;
Name of created variable:存放提取出的值的参数。
XPath Query:用于提取值的XPath表达式。
Match No 匹配数字:取第几个匹配结果,0随机,-1全部,1代表第一个,2代表第二个,….以此类推
Default Value:参数的默认值。
Namespaces aliases list:命名空间别名列表。就是这个功能,能让使用命名空间比使用旧的XPath提取器更方便。关于命名空间含义,可以看官方文档:XML 命名空间,但是写的不够详细,详细的参考这里:XML 命名空间(XML Namespaces)介绍以及节点读取方法。由于XPath2对于表达式的要求比较严格,对于带命名空间的XML(包括默认的命名空间),使用不带命名空间前缀的表达式是查询不到结果的。
3.7BeanShell 后置处理程序
BeanShell 后置处理程序,如果请求返回的消息为xml或html格式的,可以用XPath2提取器来提取需要的数据。这个估计是JMeter5.0新加的吧,具体用法和Xpath提取器的应该差不多的,可以参考上边Xpath提取器的用法。
1、我们先来看看这个 BeanShell 后置处理程序长得是啥样子,路径:线程组 > 添加 > 后置处理器 > BeanShell 后置处理程序,如下图所示:
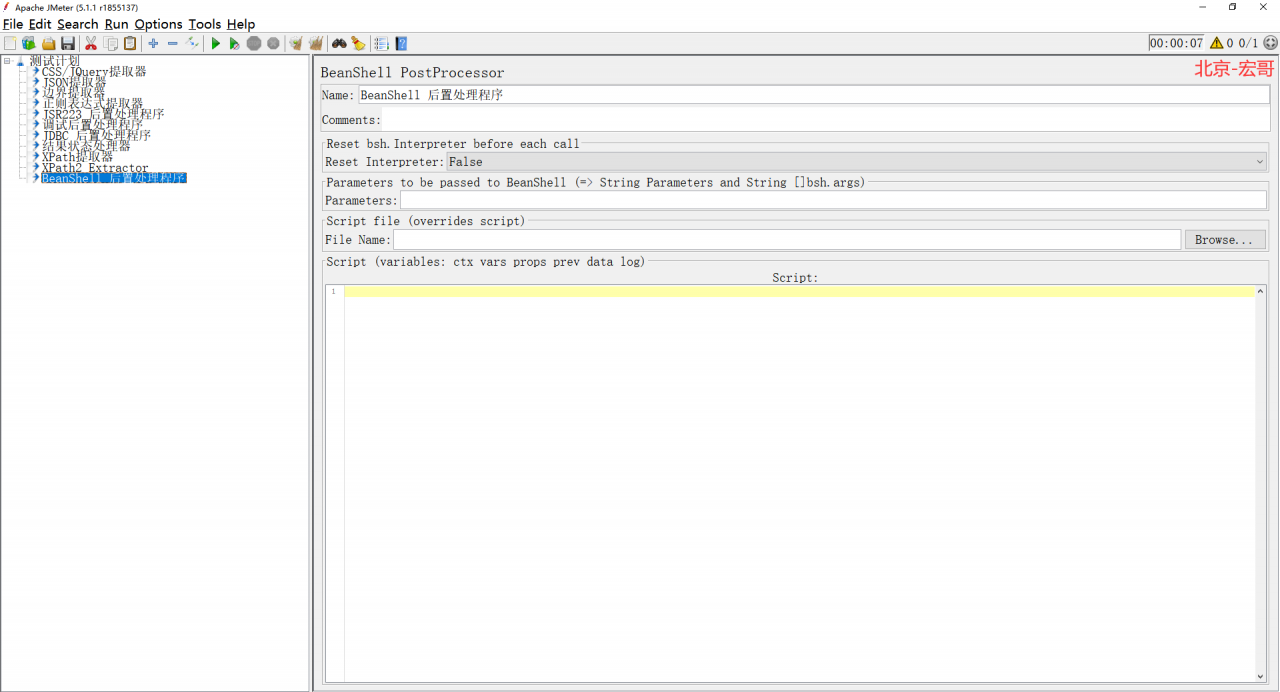
2、关键参数说明如下:
Reset bsh.Interpreter before each call: 每次迭代是否重置解释器
Reset Interpreter :false
Parameters to be passed to BeanShell(=>String Parameters and String []bsh.args) 参数传递,字符串或者数组
Parameters:
Script file(overrides script): 脚本文件
File Name:
Script(variables:ctx vars props prev data log): 脚本编辑()
3.7.1实例
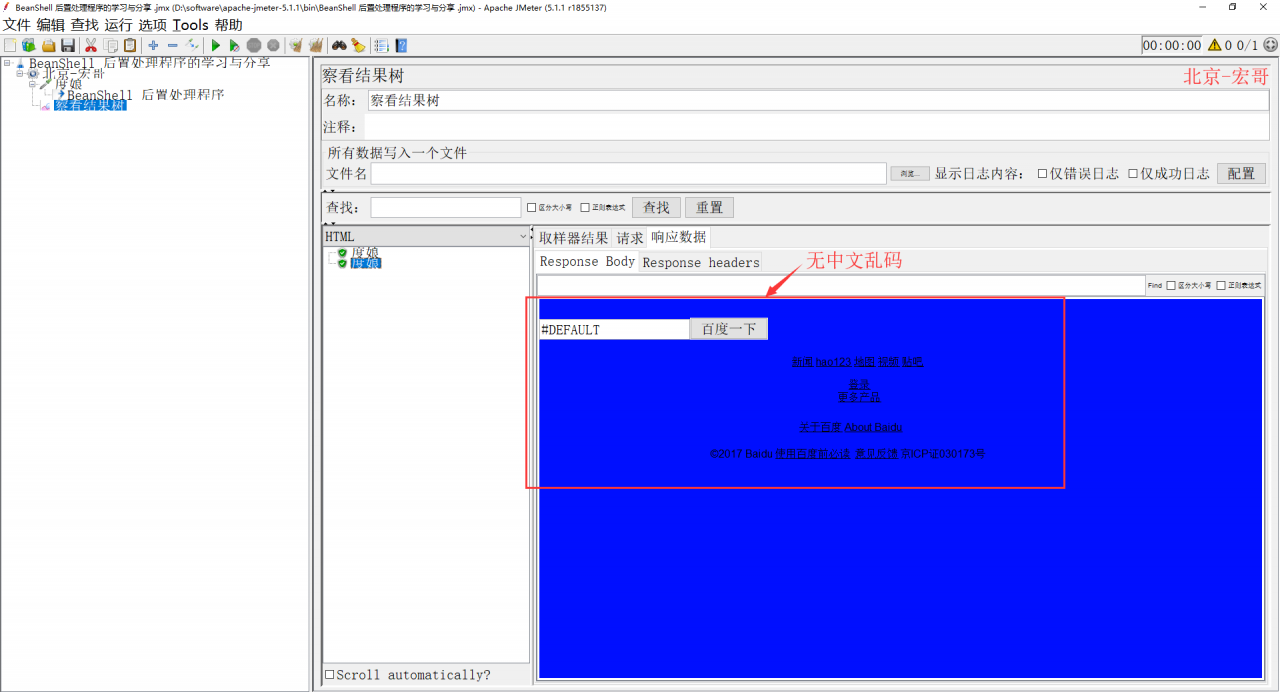
在这里宏哥就列举一个简单的例子,响应结果中有中文乱码,使用BeanShell 后置处理程序来处理中文乱码。
1、新建测试计划,线程组下添加1个取样器 访问度娘,如下图所示:

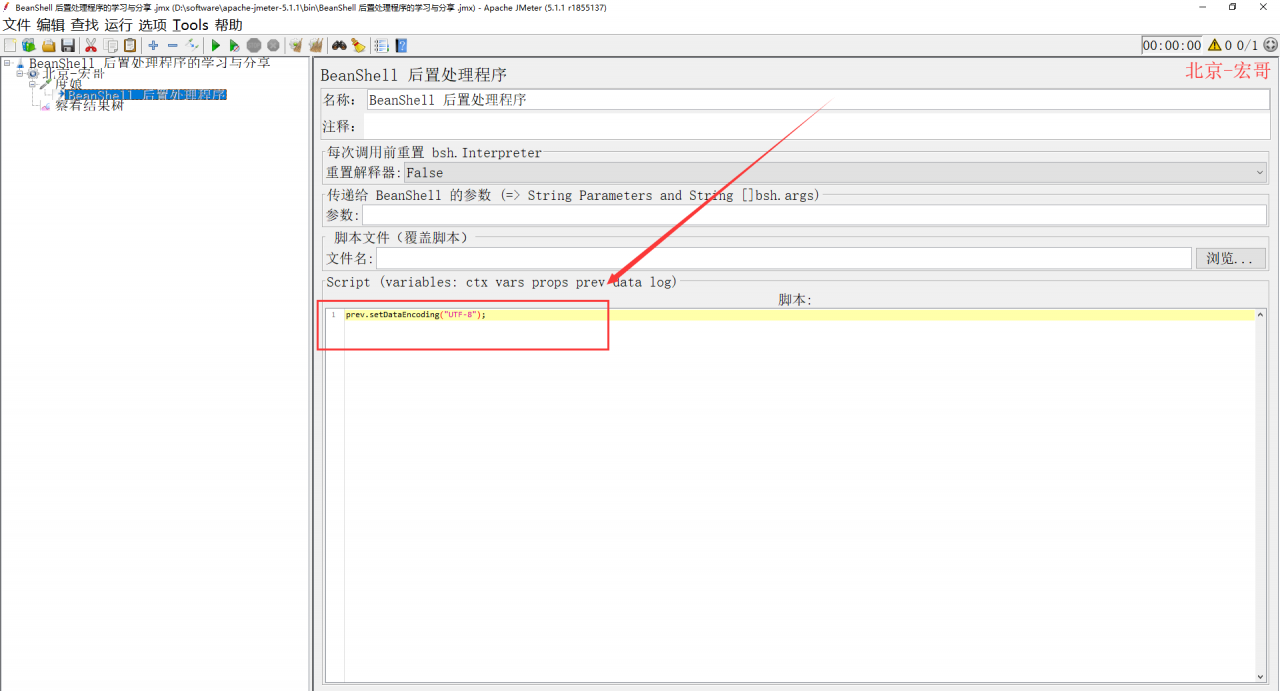
2、然后再添加BeanShell 后置处理程序,设置脚本:prev.setDataEncoding(“UTF-8”); ,如下图所示:
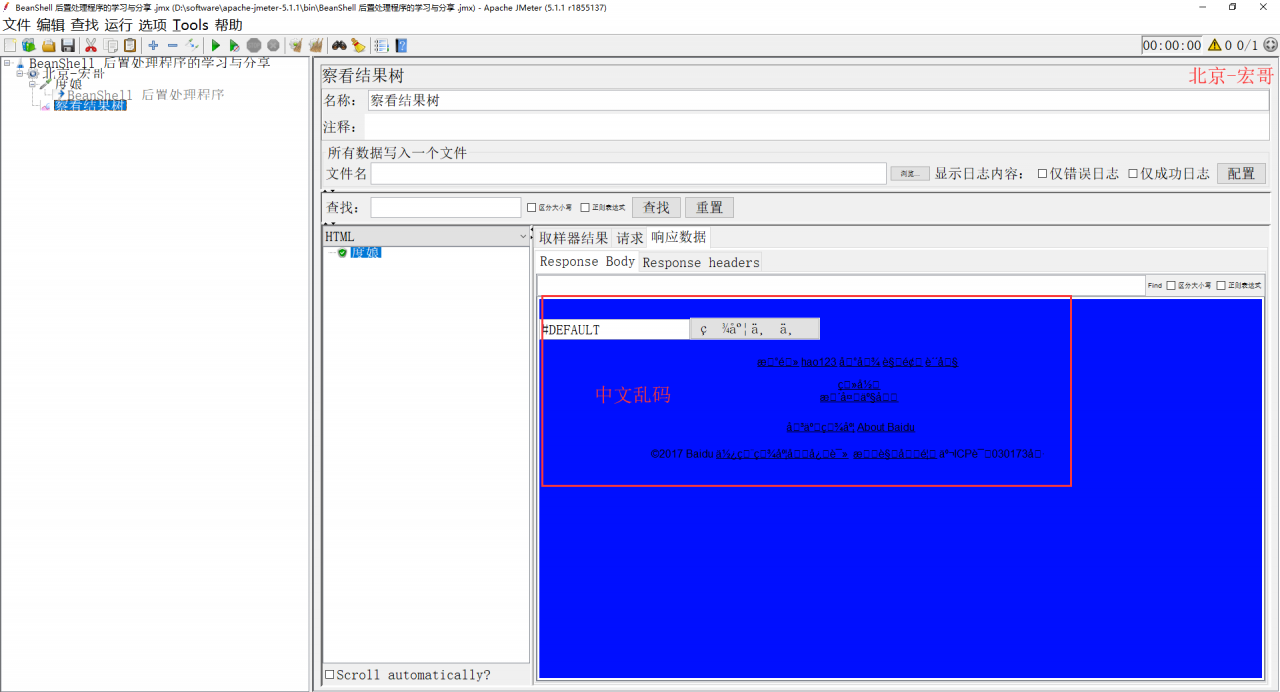
3、配置好以后,点击“保存”,运行JMeter,禁用BeanShell 后置处理程序,查看表格结果(中文乱码),如下图所示:
(1)禁用BeanShell 后置处理程序,查看表格结果(有中文乱码)
(2)启用BeanShell 后置处理程序,查看表格结果(无中文乱码)
4.小结
好了,今天到这里所有的JMeter后置处理器就全部介绍分享完了,感谢您的耐心阅读!!!
作者:北京-宏哥 | 来源:http://39sd.cn/52D30
